During GTC 2018 NVIDIA and ARM announced a partnership that will see ARM integrate NVIDIA's NVDLA deep learning inferencing accelerator into the company's Project Trillium machine learning processors. The NVIDIA Deep Learning Accelerator (NVDLA) is an open source modular architecture that is specifically optimized for inferencing operations such as object and voice recognition and bringing that acceleration to the wider ARM ecosystem through Project Trillium will enable a massive number of smarter phones, tablets, Internet-of-Things, and embedded devices that will be able to do inferencing at the edge which is to say without the complexity and latency of having to rely on cloud processing. This means potentially smarter voice assistants (e.g. Alexa, Google), doorbell cameras, lighting, and security around the home and out-and-about on your phone for better AR, natural translation, and assistive technologies.
Karl Freund, lead analyst for deep learning at Moor Insights & Strategy was quoted in the press release in stating:
“This is a win/win for IoT, mobile and embedded chip companies looking to design accelerated AI inferencing solutions. NVIDIA is the clear leader in ML training and Arm is the leader in IoT end points, so it makes a lot of sense for them to partner on IP.”
ARM's Project Trillium was announced back in February and is a suite of IP for processors optimized for parallel low latency workloads and includes a Machine Learning processor, Object Detection processor, and neural network software libraries. NVDLA is a hardware and software platform based upon the Xavier SoC that is highly modular and configurable hardware that can feature a convolution core, single data processor, planar data processor, channel data processor, and data reshape engines. The NVDLA can be configured with all or only some of those elements and they can independently them up or down depending on what processing acceleration they need for their devices. NVDLA connects to the main system processor over a control interface and through two AXI memory interfaces (one optional) that connect to system memory and (optionally) dedicated high bandwidth memory (not necessarily HBM but just its own SRAM for example).
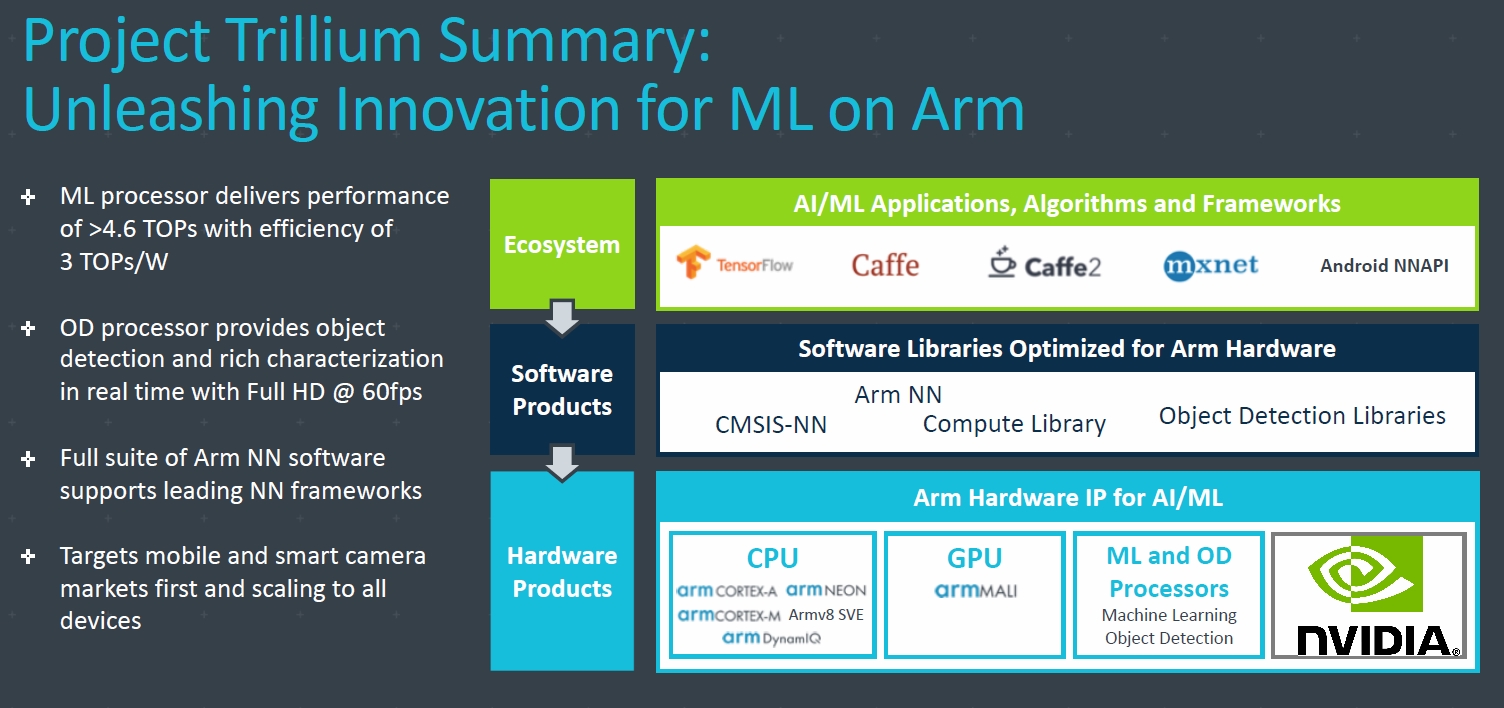
NVDLA is presented as a free and open source architecture that promotes a standard way to design deep learning inferencing that can accelerate operations to infer results from trained neural networks (with the training being done on other devices perhaps by the DGX-2). The project, which hosts the code on GitHub and encourages community contributions, goes beyond the Xavier-based hardware and includes things like drivers, libraries, TensorRT support (upcoming) for Google's TensorFlow acceleration, testing suites and SDKs as well as a deep learning training infrastructure (for the training side of things) that is compatible with the NVDLA software and hardware, and system integration support.
Bringing the "smarts" of smart devices to the local hardware and closer to the users should mean much better performance and using specialized accelerators will reportedly offer the performance levels needed without blowing away low power budgets. Internet-of-Things (IoT) and mobile devices are not going away any time soon, and the partnership between NVIDIA and ARM should make it easier for developers and chip companies to offer smarter (and please tell me more secure!) smart devices.
Also read:
- NVDLA Primer
- Project Trillium: Machine Learning on ARM
- NVIDIA Announces DGX-2 with 16 GV100s & 8 100Gb NICs
- GTC 2018: NVIDIA Announces Volta-Powered Quadro GV100
- NVIDIA Teases Low Power, High Performance Xavier SoC That Will Power Future Autonomous Vehicles
- NVIDIA Launches Jetson TX2 With Pascal GPU For Embedded Devices
- ARM Announces Project Trillium, a New Dedicated AI Processing Family